自分の忘備録用です.他の事務処理にも応用が利くと思いますので,ここに公開します. ネタ切れのせいか当初の目的からどんどんずれていくwww
遠隔授業という環境で,学生さんのプレゼン発表を聞かなければならない状況になりました.
対面なら他の学生さんも聴講する様子が一目瞭然ですが,リモートでは自分の発表時間以外に何をしているのか把握できません.
その対策として,学生さん同士でプレゼンの評価をしてもらうことにしました.
「他の人の発表をちゃんと聞きなさい」というメッセージ付きです.
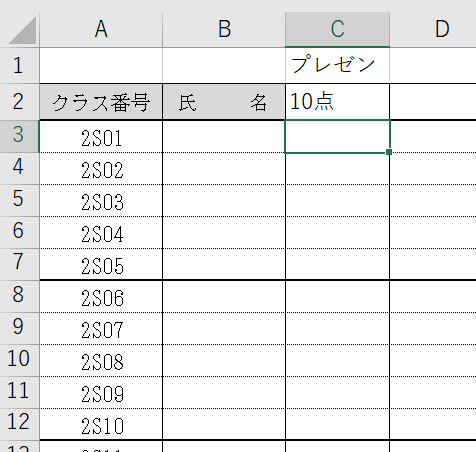
配布するのは下図のようなエクセルファイルです.個人情報保護の観点から配布データに名前は入れません.
これに各自の評価を入力してもらい,全員発表が終わればMoodleの課題提出機能を使ってアップロードしてもらいます.
これを1クラス(約40名)分集計し,合計得点の高い人にプレゼン大賞を授けるにはどうすればいいでしょうか?
まさか手動で集計しませんよね.
Pandasのおかげで簡単に記述できます.
ポイントはクラス番号と氏名が入力されたCSVを別に用意し,このCSVをベースにDataFrameの基礎情報を作ります.
そこに各学生が入力した[10点]の列を足していく,という処理になります.
ファイル名で列を追加するのでエラー処理のリカバリにもなります.
pandas, numpy の各ライブラリは
> pip install pandas
import glob
import pandas as pd
import numpy as np
# 名簿と列構成の取り込み(空のDataFrame)
# エクセルデータと区別するためにCSV形式で提供
df = pd.read_csv('2S名簿.csv', header=0, index_col=0)
# カレントのエクセルファイルを全て読み込み
# ファイル名で列を追加
# 隠しファイルも対象になるのでエクセルは閉じておくように
list = glob.glob('*.xlsx')
type = [int, np.int64, float, np.float64]
for f in list:
print('file='+f+' start', end='')
ex = pd.read_excel(f, header=1, index_col=0) # 2行目がヘッダー, 1列目がインデックス
if ex['10点満点'].dtype in type: # 型のチェック
print('')
else:
print(' --- not numeric ', end='')
print(ex['10点満点'].dtype)
ex['10点満点'] = pd.to_numeric(ex['10点満点'], errors='coerce')
df[f] = ex['10点満点'].fillna(0) # NaNはゼロで置換
# 合計と平均を算出
sum = df.sum(axis='columns', numeric_only=True)
ave = df.mean(axis='columns', numeric_only=True)
# 名前の次に結果を挿入
df.insert(1, '順位', sum.rank(method='min', ascending=False))
df.insert(2, '合計', sum)
df.insert(3, '平均', ave)
# 合計点数で降順に並べる
# 同点の場合は番号昇順
df = df.sort_values(['合計', '番号'], ascending=[False, True])
df.to_excel('../2S合計.xlsx')
print('')
print(df)
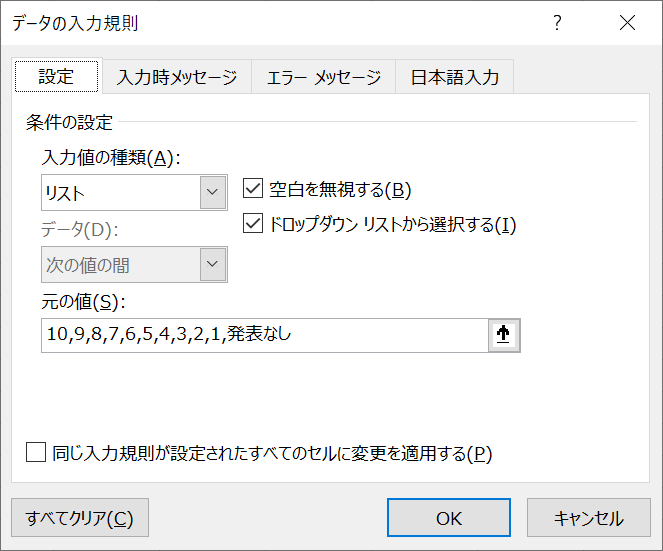
まれに全角数字や変な入力をする学生がいるので, エクセルの方で[データの入力規則]を設定しておくと尚良しですね. 上のエラー処理はこの設定をする前のものです.後学のため入れたままにしています.