著書『いまからはじめるNC工作 第2版』p.47 図2.25 で少しだけ触れており, Excelで作られた 帳票作成マクロ(ページ一番下) もダウンロードできるようにしてあります. ですが,Excelのマクロって社内などの仲間うちで使うには何も気にしなくて良いですけど,ネットからダウンロードするマクロって怖いイメージがありますよね. これをPythonで作ってみました.ソースがオープンになっているので,安心して使えると思います.
import sys
import os
import re
import pandas as pd
## 使い方
## python procsheet.py sample.ncd [sample.xlsx]
## 最後の出力ファイル名は省略可.省略すると 入力ファイル.xlsx で出力されます
## 引数処理
inFile=open(sys.argv[1])
outFile=os.path.splitext(sys.argv[2 if len(sys.argv)>2 else 1])[0]+'.xlsx'
#print(outFile)
## 無視する行とワード処理する正規表現
reg_ignore = re.compile(r'^%|\(.*?\)|[\r\n]$')
reg_progno = re.compile(r'O\d+')
reg_word = re.compile(r'[A-Z/]-?\d*\.?\d*')
## プロセスシートの列をDataFrameで作成
col = ['/','N','G','X','Y','Z','R/I','J','K','F','S','T','M','H/D','L','P','Q']
df = pd.DataFrame(index=[], columns=col)
prog='' ## O番号
## 1行(ブロック)ずつ処理
with open(inFile) as f:
for line in f:
## 先頭の%とカッコ内のコメントと行末の改行は''に置換
line = reg_ignore.sub('', line)
if len(line)==0:
continue
## プログラム番号
wordlist = reg_progno.findall(line)
for word in wordlist:
prog += word + ' '
## ブロックをワードごとに分割
dic = {}
wordlist = reg_word.findall(line)
for word in wordlist:
## ワードの先頭1文字をキーに各列に文字列を追加
w = word[:1]
if w=='R' or w=='I':
w = 'R/I'
elif w=='H' or w=='D':
w = 'H/D'
elif w=='O': ## O番号は列として登録しない
continue
dic[w] = (dic.get(w) or '') + word
## DataFrameに1行追加
df = df.append(dic, ignore_index=True)
#print(df)
df.to_excel(outFile, index=False, startrow=4) ## 4行空けて出力
procsheet.py
(実際のコードは罫線などの飾り付けも含まれます)
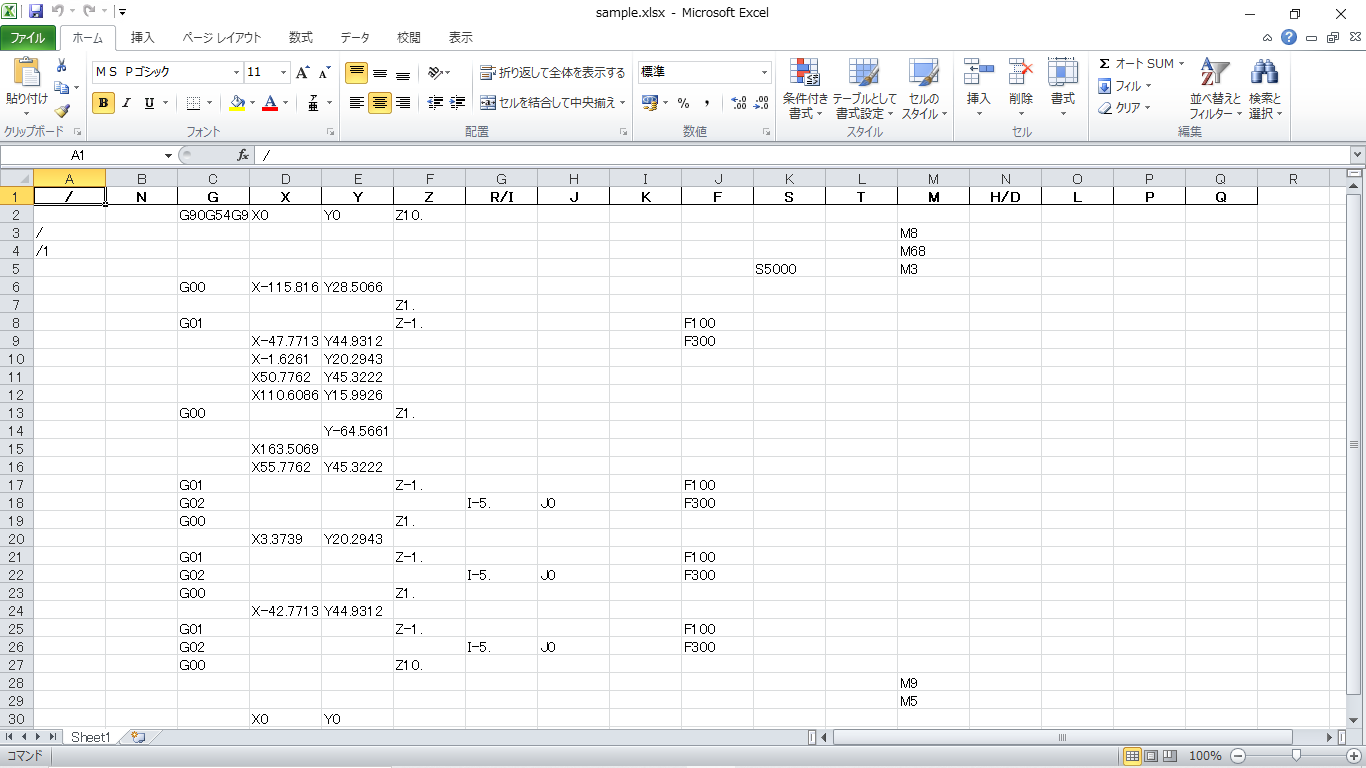
これを実行すると,以下のようなExcelファイルが出力されます.
暗号のような正規表現のところだけ解説を加えます.
まず reg_ignore = re.compile(r'^%|\(.*?\)|[\r\n]$') のところ.
次に reg_word = re.compile(r'[A-Z/]-?\d*\.?\d*') のところ.
これで1つのワードにマッチします.
あとは煮るなり焼くなり好きに使ってください.NCVC本体インストーラに同梱予定です.